Difyのhttpブロックを使えば、外部のデータベースとも簡単に連携できます。
この記事では、”Firestore”にデータを格納するコードを書いてみます。
Firestoreは、GoogleのバックエンドサービスであるFirebaseに含まれるデータベースです。
Firebaseは、アプリのフロントエンド開発者がよく使う、ユーザ認証、ホスティング、データベース、ストレージなどを簡単に利用できるように工夫されたサービスです。
FirebaseはGoogleCloudPlatformの上で動いていますので、GCPと同じプロジェクトで動作することができます。
Firebaseの設定
Firebaseの詳細な説明は割愛いたします。Firebaseについては、以下の公式サイトをご覧ください。

Firebaseにアクセスできるようになったら、プロジェクトを作成しておきます。
データ形式
FirestoreはNoSQLなので、あらかじめデータ構造を決めておく必要はありません。今回は、汎用的な形として、以下の形式を基本とします。
author:<データの作成者>
category:<データのカテゴリ>
created_at:<データの作成日時>
text:<生成されたテキスト>CloudFunction
CloudFunctionは、小さなタスクをサーバレスで実現できる仕組みです。Difyからデータベースに直接アクセスするのではなく、CloudFunctionを介してアクセスするようにします。
以下は、Jsonの形式でもらったデータをFirebaseに格納するだけのコードです。Firebaseのプロジェクトと同じプロジェクトにデプロイすると簡単に実装できます。
import functions_framework
import firebase_admin
from firebase_admin import credentials, firestore
import os
import json
# Firebase Admin SDKの初期化
# Secret Managerから環境変数で秘密鍵を取得
cred_json = os.environ.get('FIREBASE_CREDENTIAL')
if cred_json:
cred_dict = json.loads(cred_json)
cred = credentials.Certificate(cred_dict)
firebase_admin.initialize_app(cred)
else:
# Workload Identityを使用する場合
firebase_admin.initialize_app()
# Firestoreクライアントの初期化
db = firestore.client()
@functions_framework.http
def save_to_firestore(request):
# CORSヘッダーの設定
headers = {
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': 'POST',
'Access-Control-Allow-Headers': 'Content-Type',
'Content-Type': 'application/json; charset=utf-8'
}
# プリフライトリクエストの処理
if request.method == 'OPTIONS':
return ('', 204, headers)
# POSTリクエストのみ許可
if request.method != 'POST':
return ('Method Not Allowed', 405, headers)
try:
# リクエストボディからデータを取得
data = request.get_json()
# テキスト、メタデータ、コレクション名の抽出
text = data.get('text')
metadata = data.get('metadata', {})
collection_name = data.get('collection', 'generated_texts') # デフォルト値を設定
# 必須パラメータのチェック
if not text:
return (json.dumps({
'message': 'Text parameter is required'
}, ensure_ascii=False), 400, headers)
# Firestoreにデータを保存
doc_ref = db.collection(collection_name).add({
'text': text,
'created_at': firestore.SERVER_TIMESTAMP,
**metadata
})
# 成功レスポンス
return (json.dumps({
'message': 'Text saved successfully',
'document_id': doc_ref[1].id,
'collection': collection_name
}, ensure_ascii=False), 200, headers)
except Exception as e:
# エラーハンドリング
print(f'Error saving to Firestore: {str(e)}')
return (json.dumps({
'message': 'Error saving text',
'error': str(e)
}, ensure_ascii=False), 500, headers)Dify
以下のワークフローは、「経済ニュースのトピックをまとめて、データベースに保存する」ものです。

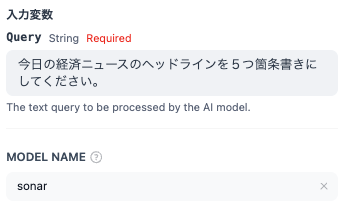
- Perplexity Search
-
Webを検索して、情報を収集します。

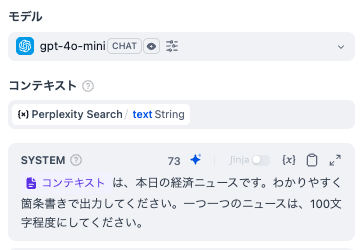
- LLM
-
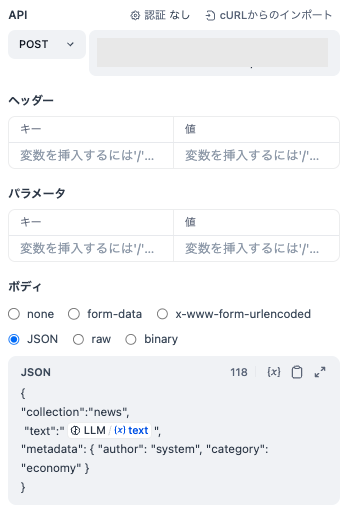
- HTTPリクエスト
-
-
APIにはCloudFunctionのURLを設定します。
実行結果
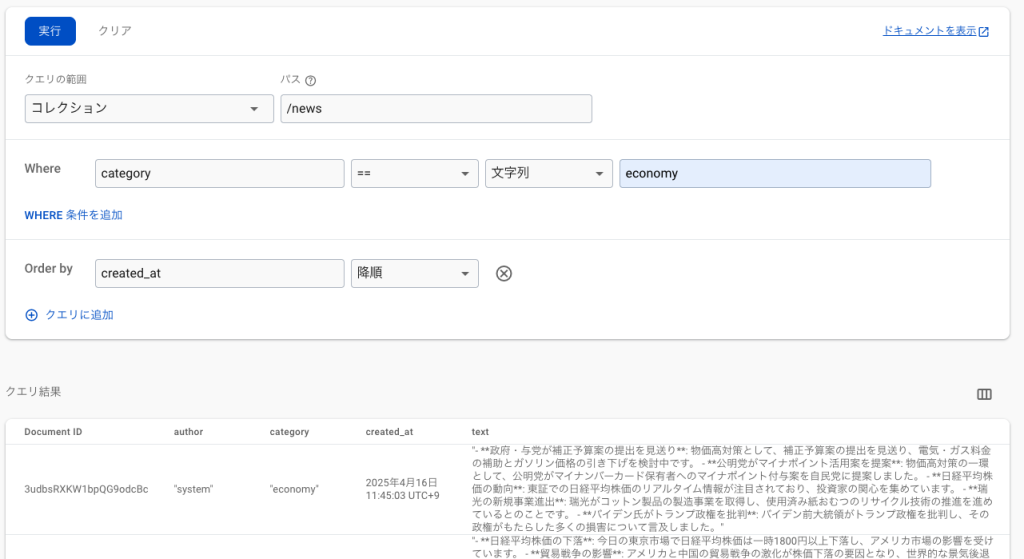
このワークフローを実行すると、Firestoreにデータが格納されているのが分かります。
まとめ
Difyのワークフローで生成したテキストをDBに格納するAPIを実装してみました。このように格納されたDBは同様の仕組みで、Difyから利用することも可能です。
また、このワークフローを呼び出す CloudRunを作成して、定期的(例えば、毎朝6時に)自動実行しておけば、利用者全員で同じ情報にアクセスすることができます。
今回は、webのニュースソースを使いましたが、社内の情報を定期的にまとめて、DB から利用しやすい形にすることもできます。
DBと繋がることで、生成AIの可能性も一気に広がるかと思います。