チャットフローを使えば、チャットボットよりも複雑な処理を実現できます。
基本のチャットフロー
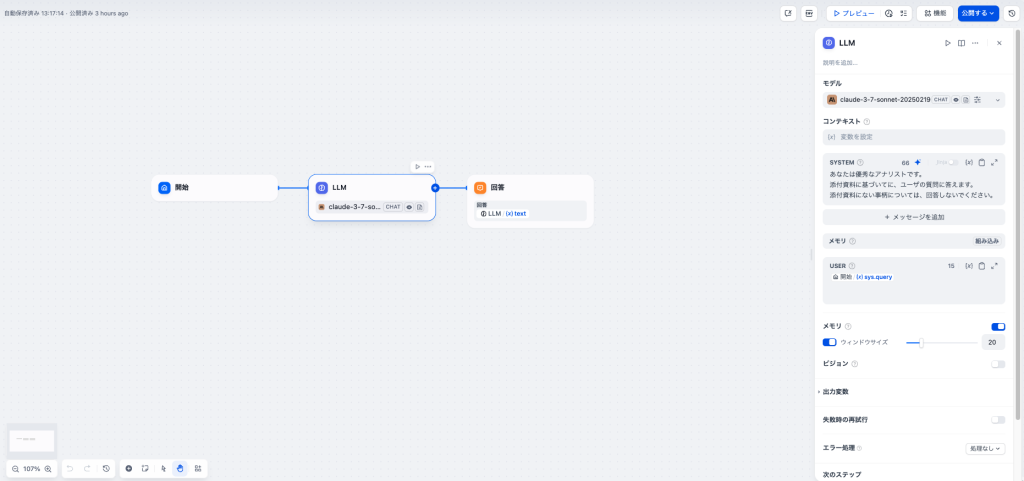
基本のチャットフローは、3つのブロックからなります。
- 開始
-
会話の開始ブロックです。これはチャットフローアプリの必須ブロックです。会話に対する初期情報を提供します。デフォルトのシステム変数に加えて、ユーザがアップロードしたファイルの情報などが含まれます。
- LLM
-
利用するLLMモデルとパラメータを設定します。
- モデル名 (事前にモデルプロバイダーで設定が完了しているもの)
- システムプロンプト
- LLMパラメータ(Temperature, Top P, MaxTokensなど)
- 回答
-
ユーザに対する回答を指定します。通常はLLMからの出力textを出力します。必要に応じて他の変数と組み合わせたり、書式を変更することもできます。
例えば、アップロードされたファイル名や、日付を追加して出力することができます。
基本のブロック
以下に、チャットフローでよく利用するブロックについて説明します。
- 知識獲得
-
RAGを実現するためのブロックです。あらかじめ作成したナレッジを参照して、LLMに回答させたい場合に使います。
- 質問分類器
-
ユーザからの質問によって処理を変えたい場合に使います。例えば、質問の内容によって、参照するナレッジを変更したり、使用するLLMを変更することができます。
- IF/ELSE
-
チャットフローのロジックを制御するためのブロックです。変数を使うことで条件分岐が可能です。
- コード
-
簡単なプログラムコードを埋め込むことができます。言語としては、python3,JavaScriptが使えます。
例えば、現在の時刻を取得して、変数に設定するなどできます。from datetime import datetime, timedelta, timezone def main(): # 日本時間(UTC+9)のタイムゾーンを定義 jst = timezone(timedelta(hours=9)) # 現在の日時を日本時間で取得 current_datetime_jst = datetime.now(jst).strftime('%Y-%m-%d %H:%M:%S') # 出力として次に渡す result = {"current_datetime": current_datetime_jst} return result - テキスト抽出ツール
-
通常、LLMは文書ファイルの内容を直接読み取ることができません。そこで、ファイルからテキスト部分のみを抽出した結果を、LLMの入力とします。
サポートするファイル形式は、以下の通りです。
txt,markdown,mdx,pdf,html,xlsz,xls,docx,doc,csv,md,hml - HTTPリクエスト
-
HTTP プロトコルを介してサーバーにリクエストを送信することを可能にし、外部データの取得、ウェブフック、画像生成、ファイルのダウンロードなどのシナリオに利用されます。
サンプルコード 感情判定付きチャット
簡単な事例として、感情判定付きのチャットをチャットフローで作ってみます。
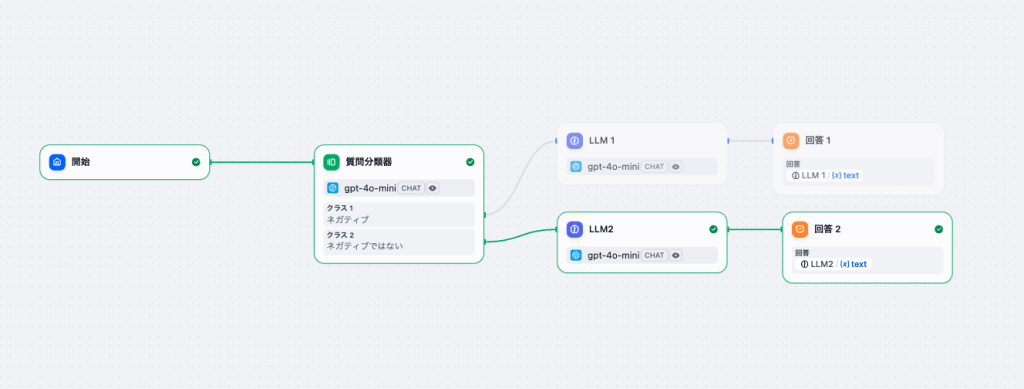
- 質問分類器
-
質問分類器では、ユーザの入力がネガティブか、そうでないかを判定します。
ネガティブだった場合には、LLM1へ、そうでなかった場合には、LLM2へ進みます。 - LLM
-
まず、2つのプロンプトの「メモリ」をOnにします。これによって、直近の会話履歴を使いながら、自然が会話ができるようになります。
LLM1のプロンプトは以下のようにします。
あなたは感情に寄り添ったアシスタントです。
ユーザの意見をじっくりと傾聴してください。LLM2のプロンプトは以下のようにします。
あなたは元気いっぱいのアシスタントです。
ユーザが楽しくなるように、積極的に話しかけてください。これによって、ネガティブな場合には、相手の話を聴くようになり、そうでなかった場合には、積極的に話題を広げるような会話をします。
以上のように、チャットフローではチャットボットよりも複雑な処理を実現することができます。
例えば、顧客サポートボットでは、操作方法の問い合わせ、その他の問い合わせ、クレームなどを分類して、その後の処理方法を変えることができます。
