Difyでは、様々な文書をナレッジとして登録しておき、チャットフローなどから利用することができます。
文書の登録
ファイルアップロード
データソースとして利用可能なものは、以下の通りです。
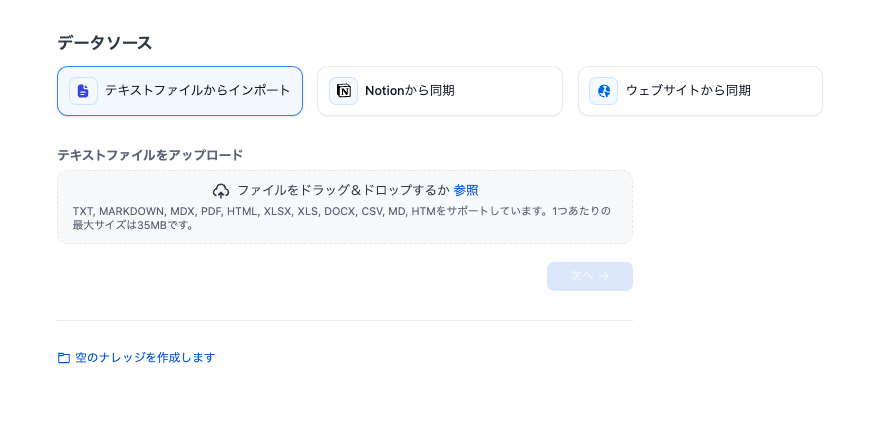
まずは、テキストファイルからインポートを試してみます。
txt以外の場合は、含まれているテキストを抽出した上で、データベースに登録することになります。
ここでのデータベースは、ベクトルデータベースというものです。文章を全てベクトルに変換して登録することで、LLMが類似文章を見つけやすくなっています。
対象となる文書がtxt以外の場合には、別途前処理を行うことで検索効率が上がる場合があります。
チャンク設定
チャンクとは、一塊の文章のことです。入力されたテキストを、一定のサイズに分割します。
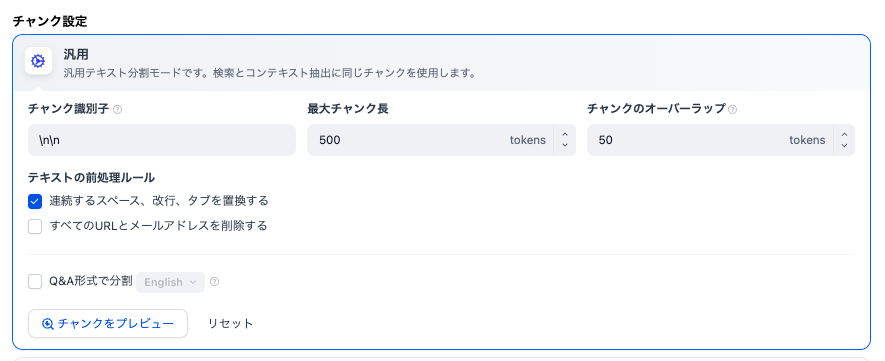
- チャンク識別子
-
チャンクを強制的に分割する文字列です。”\n\n”は段落を切れ目とします。複数の識別子を”,”で区切って設定することもできます。
- 最大チャンク長
-
一つのチャンクの最大長を設定します。一般には、500〜1000程度が良いとされています。
- チャンクのオーバーラップ
-
チャンクの切れ目でをオーバラップさせることで、チャンク間の連続性を保ちます。一般には、チャンク長の10%程度を設定します。
- テキストの前処理ルール
-
チャンク分割の前に、テキストに対して前処理を行います。ここに記載されている以外の前処理は、プログラムで処理を記述します。
- QA形式で分割
-
文書から自動的に「よくある質問」を想定し、QA形式に変換されます。FAQ応答に利用するナレッジでは、特に有効だと思います。
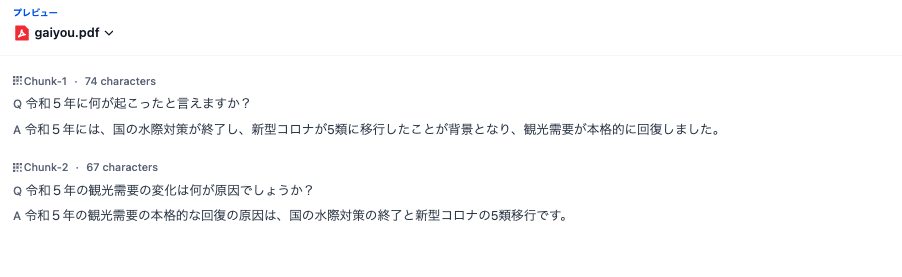
「チャンクをプレビュー」すると、どのように分割されるのかが確認できます。
以下の文書をQA形式で分割した場合の例です。
タイトル:令和5年京都観光総合調査結果【概要】
形式:PDF 5ページ
URL:https://www.city.kyoto.lg.jp/sankan/cmsfiles/contents/0000313/313644/gaiyou.pdf
※グラフ、表、コメントなどが含まれています。
埋め込みモデル
チャンクをベクトル化する時に使用するモデルです。次元数が大きいほど情報量が増えて、検索の精度が上がります。コストがかかりますが、精度を上げるためにはtext-embedding-3-largeを選択すると良いかと思います。コストが気になる場合には、voyageも選択肢になります。
検索設定
検索方法の設定は、対象となる文書によって最適解が異なりますが、通常はハイブリッド検索がおすすめです。
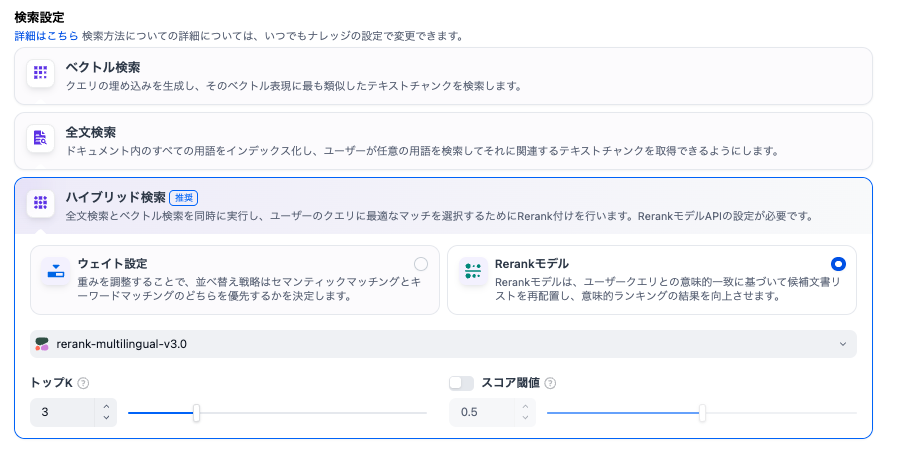
ハイブリッド検索は、ベクトル検索と全文検索(キーワード)とを組み合わせた検索です。さらにRerankモデルを設定しておくことで、検索精度は上がります。
「保存して処理」を押すと、データベースの作成が始まります。
関連する文書が複数ある場合には、「ファイルを追加」して同様に登録作業をおこまいます。
全ての文書のステータスが「利用可能」になれば、ナレッジ化の完了です。
(参考)ナレッジ登録の自動化
定型的なナレッジの登録はプログラムからも実行可能です。例えば、「月例報告」のようなものがあれば、所定のフォルダにおくことで、自動で登録することも可能です。
