なぜRAGが必要なのか?
現代の大規模言語モデルは驚異的な能力を持っていますが、いくつかの重要な制約があります:
- 知識の鮮度の問題:大規模言語モデル(LLM)は膨大な情報を事前学習することによって作られます。そのため、この学習の時点で「凍結」された知識しか持ちません。例えば、2023年までのデータで学習したモデルは、2024年以降の出来事についての情報が含まれていません。
- ハルシネーション(幻覚):LLMは自信満々に間違った情報を生成することがあります。
- 専門知識の限界:特定の組織や分野の専門的な情報には弱いことがあります。これは事前学習のデータの範囲に依存しています。
- ソースの不透明性:LLMは回答の情報源を明示できないため、信頼性の検証が困難です。
- コンテキスト長の制限:現在ではLLMに情報を与えながら質問することもできます。しかし、一度に処理できる情報量には制限があります。
RAG(Retrieval-Augmented Generation)は、上記の制約に対する有効な解決策を提供します:
RAGの構造
RAGの処理を細かく見ると、以下の図ように分けることができます。
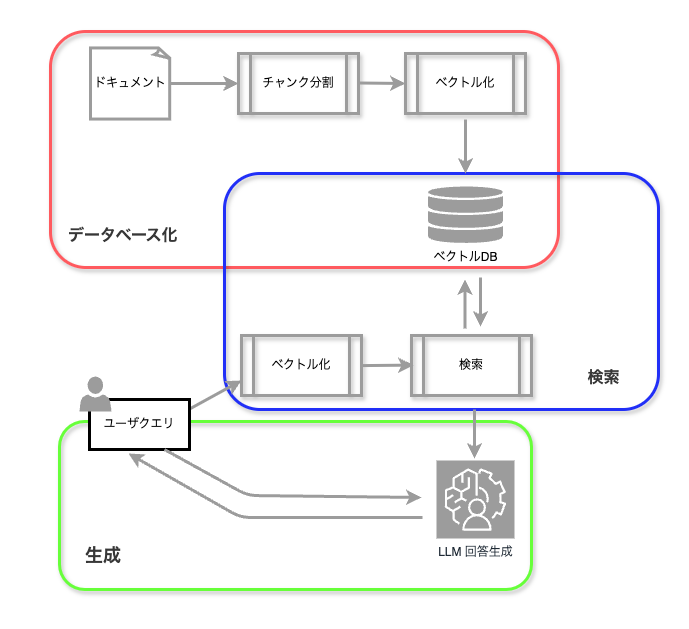
データベース化
- ドキュメント: 社内文書、営業資料など様々なソースからデータを収集・整形する
- チャンク分割: 大きなドキュメントを適切な大きさに分割
- ベクトル化(エンベッディング): 各チャンクをベクトル表現に変換
- メタデータ付与: 出典、日付、カテゴリなどの情報を追加
- ベクトルデータベースへの格納: Chroma、Pinecone、Weaviateなどのベクトルデータベースに格納
検索(Retrieval)
- ベクトル化(エンベッディング): ユーザークエリをDB作成時と同じエンベッディングモデルでベクトル化
- フィルタリング: メタデータを使用して検索対象を絞り込み
- 検索: ベクトル類似度等に基づいて関連性の高い情報を検索
生成(Generation)
- プロンプトエンジニアリング: 検索結果を組み込んだ効果的なプロンプト設計
- 回答生成: LLMによる回答の生成
- 評価と改善: 生成された回答の評価と改善
RAGプロンプト
RAGシステムでは、効果的なプロンプト設計が重要です。以下は典型的なRAGプロンプトの構造です:
システム指示:
あなたは正確で有用な情報を提供するアシスタントです。以下のコンテキスト情報に基づいて質問に答えてください。
コンテキスト情報に含まれていない場合は、「その情報はコンテキストに含まれていません」と正直に答えてください。
回答ではコンテキスト情報の関連部分を引用し、ソースを明示してください。
コンテキスト情報:
[検索システムから取得した関連情報をここに挿入]
ユーザーの質問:
[ユーザーの質問をここに挿入]
プロンプト最適化テクニック
- 情報の階層化: 最も関連性の高い情報を先に配置する
- ソース明示: 各情報の出典を明確に示すように指示する
- 指示の明確化: AIに期待する回答形式を明示する
- Few-shotの活用: 期待する回答の例を示す
- ガイドラインの提示:回答を生成する上での手順、制約などを示す
最新のLLMモデルでは段階的な思考がモデルに組み込まれており、プロンプトの最適化手法は少し変わってきています。モデルの特性と全体の処理構造を理解した上で、モデルの選定とプロンプトの設定をする必要があります。
RAGサンプルコード
以下はLangChain-Pythonを使用したRAG実装の基本的なサンプルコードです:
Difyを使うとノーコードで実現できますが、RAGの内部処理を理解しておくことで、改善のポイントが見えてくることもあります。
import os
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
# 環境変数の設定
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
# 1. ドキュメントの読み込み
loader = TextLoader("./data/document.txt")
documents = loader.load()
# 2. ドキュメントのチャンク化
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
)
chunks = text_splitter.split_documents(documents)
# 3. エンベッディングとベクトルDBの構築
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(
documents=chunks,
embedding=embeddings,
persist_directory="./chroma_db"
)
# 4. 検索用リトリーバーの作成
retriever = vectordb.as_retriever(search_kwargs={"k": 3})
# 5. RAGシステムの構築
llm = OpenAI(temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever,
return_source_documents=True
)
# 6. クエリの実行
query = "この文書の主要なポイントは何ですか?"
result = qa_chain({"query": query})
# 7. 結果の表示
print("回答:", result["result"])
print("\n参照ソース:")
for i, doc in enumerate(result["source_documents"]):
print(f"ソース {i+1}:\n{doc.page_content}\n")
まとめ
RAGの機能は強力ですが、それでも100%正しい答えが返ってくる保証はありません。 特に図やグラフの解釈や推論を必要とする回答は、まだ発展途上と言わざるを得ません。
しかし、適切なベクトルDBの構築、LLMの選定、プロンプトの改善などで正答率は上がってきます。過度な期待によって「使えない」と結論づけてしまうのではなく、現在のRAGの実力を正しく理解し、業務に適切に利用することが求められるかと思います。
